728x90
k-최근접 이웃 회귀와 선형 회귀 알고리즘의 차이를 이해하고 사이킷런을 사용해 여러 가지 선형 회귀 모델을 만들어 봅니다.
k-최근접 이웃의 한계
import numpy as np
perch_length = np.array( [8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5, 44.0] )
perch_weight = np.array( [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0, 1000.0] )
- 이번에도 데이터를 훈련세트와 테스트 세트로 나눈다. 특성 데이터는 2차원 배열로 변환한다
from sklearn.model_selection import train_test_split
train_input,test_input,train_target,test_target = train_test_split(perch_length,perch_weight,random_state=42)# 2차원 배열로 변환
train_input = train_input.reshape(-1,1) test_input = test_input.reshape(-1,1)
# 최근접 이웃 개수를 3으로 하는 모델을 훈련한다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(train_input,train_target)
print(knr.predict([[50]]))
>>[1033.33333333]- 실제 농어의 무게는 이 무게보다 훨씬 더 많이 나간다....what's the problem...
- 산점도를 일단 그려보겠다...
import matplotlib.pyplot as plt
# 50cm 농어의 이웃을 구한다.
distances,indexes = knr.kneighbors([[50]])
# 훈련 세트의 산점도를 그립니다.
plt.scatter(train_input,train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그린다.
plt.scatter(train_input[indexes],train_target[indexes],marker='D')
# 50cm 농어 데이터
plt.scatter(50,1033,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()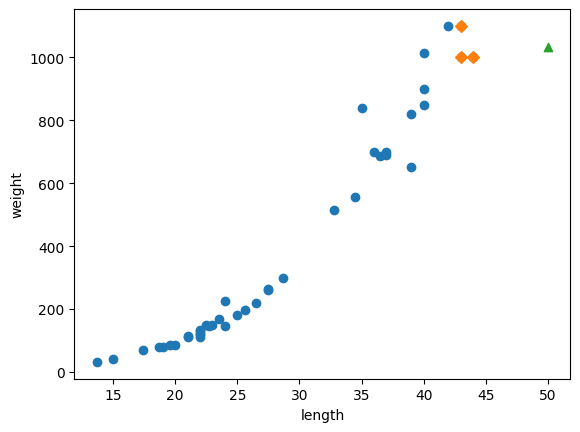
- 아하... 50cm 농어와 가장 가까운 농어가 45cm 밖에 없어서 비슷하다고 예측했구나...길이가 증가하면 무게도 증가하게 해야하는데..
print(np.mean(train_target[indexes]))
print(knr.predict([[100]]))
>>1033.3333333333333
[1033.33333333]# 100cm 농어의 이웃을 구한다
distances,indexes = knr.kneighbors([[100]])
# 훈련 세트의 산점도를 그린다.
plt.scatter(train_input,train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그린다.
plt.scatter(train_input[indexes],train_target[indexes],marker='D')
# 100cm 농어 데이터
plt.scatter(100,1033,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()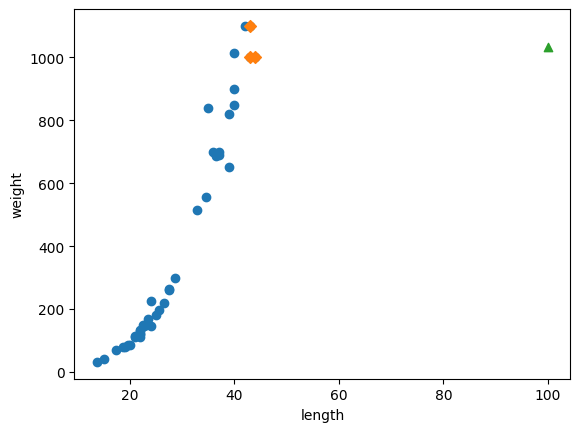
- 해결법은 가장 큰 농어가 포함되도록 훈련세트를 다시 만드는건데...매번 그럴 수도 없고...
선형회귀
선형 회귀는 널리 사용되는 대표적인 회귀 알고리즘이다. 비교적 간단하고 성능이 뛰어나 맨 처음 배우는 알고리즘 중 하나이다. 이름에서 알 수 있듯이 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘이다.
사이킷런은 sklearn.linear_model 패키지 아래에 LinearRegression 클래스로 선형 회귀 알고리즘을 구현해놨다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input,train_target)
print(lr.predict([[50]]))
>>[1241.83860323]- LinearRegression클래스는 y = ax + b 형식의 그래프를 하나 만든다. 그래서 lr 객체의 coef_와 intercept_ 속성을 보면 a,b가 저장돼 있다.
- coef_ 속성 이름에서 알 수 있듯이 머신러닝에서 기울기를 종종 계수(coefficient) 또는 가중치(weight)라고 부른다.
* coef_와 intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 부른다. 이 책에서 사용하는 많은 머신러닝 알고리즘의 훈련 과정은 최적의 모델 파라미터를 찾는 것과 같다. 이를 모델 기반 학습이라고 부른다. 반면 앞에서 사용한 k-최근접 이웃에는 모델 파라미터가 없다. 훈련 세트를 저장하는 것이 훈련의 전부이기 때문이며 이를 사례 기반 학습이라고 한다.*
print(lr.coef_,lr.intercept_)
>>[39.01714496] -709.0186449535477# 훈련 세트의 산점도를 그린다.
plt.scatter(train_input,train_target)
# 15에서 50까지 1차 방정식 그래프를 그린다.
plt.plot([15,50],[15*lr.coef_ + lr.intercept_, 50 * lr.coef_ + lr.intercept_])
# 50cm 농어 데이터
plt.scatter(50,1241.8,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()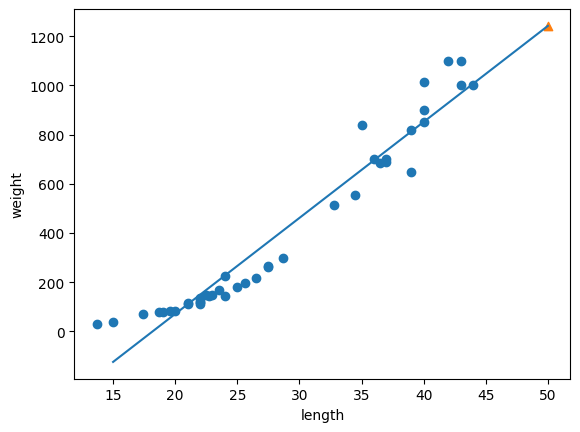
- 바로 이 직선이 선형 회귀 알고리즘이 이 데이터셋에서 찾은 최적의 직선이다.
- 그럼 이전 절과 같이 훈련 세트와 테스트 세트에 대한 결정계를 확인할 수 있다.
print(lr.score(train_input,train_target))
print(lr.score(test_input,test_target))
>>0.939846333997604
0.8247503123313558
- 엇 훈련세트에 과대적합됐다....근데 잘 보니까 그냥 둘 다 낮은거 같은데..전체적으로 과소적합인가...그래프 아래가 이상한거 같기두..
다항회귀
자알 보면 그래프 왼쪽 아랫부분이 직선으로 쭉 뻗어 있다. 아하 무게가 마이너스인 생선이 있단말인가...여기가 오올 블루인가..
그래서 2차 방적식의 그래프를 그려보려고 한다. 그러면 끝이 조금 위로 구부러질거 같다. 2차 방정식의 그래프는 길이를 제곱한 항이 훈련 세트에 추가되어야 한다.
사실 넘파이를 사용하면 아주 간단히 만들 수 있다. 2장에서 사용했던 column_stack()함수를 사용하면 아주 간단하다. train_input을 제곱한 것과 train_input 두 배열을 나란히 붙이면 된다. test_input도 마찬가지이다.
train_poly = np.column_stack((train_input**2,train_input))
test_poly = np.column_stack((test_input**2,test_input))
print(train_poly.shape,test_poly.shape)
>>(42, 2) (14, 2)- 이제 train_poly를 사용해 선형 회귀 모델을 다시 훈련하겠다. 여기서 주의할 점은 2차 방정식 그래프를 찾기 위해 훈련 세트에 제곱 항을 추가했지만, 타깃값은 그대로 사용한다. 목표하는 값은 어떤 그래프를 훈련하든지 바꿀 필요가 없다.
lr = LinearRegression()
lr.fit(train_poly,train_target)
print(lr.predict([[50**2,50]]))
>>[1573.98423528]print(lr.coef_,lr.intercept_)
>>[ 1.01433211 -21.55792498] 116.0502107827827- 무게 = 1.01 X 길이(제곱) - 21.6 X 길이 + 116.05
이런 방적식을 다항식이라 부르며 다항식을 사용한 선형 회귀를 다항 회귀라고 부른다.
# 구간별 직선을 그리기 위해 15에서 49까지 정수 배열을 만든다.
point = np.arange(15,50)
# 훈련 세트의 산점도를 그린다,
plt.scatter(train_input,train_target)
# 15에서 49까지 2차 방정식을 그래프로 그린다.
plt.plot(point,1.01 * point **2 - 21.6*point + 116.05)
# 50cm 농어 데이터
plt.scatter(50,1574,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()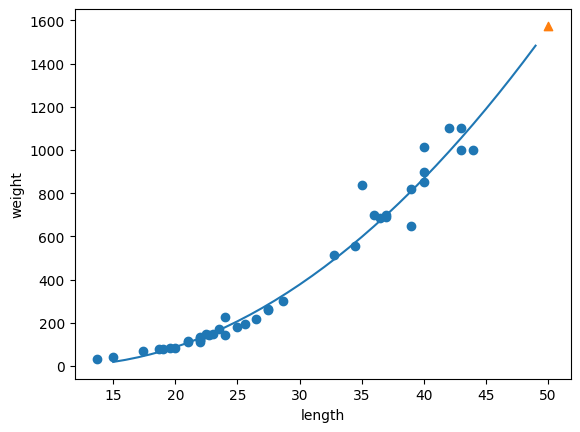
print(lr.score(train_poly,train_target))
print(lr.score(test_poly,test_target))
>>0.9706807451768623
0.9775935108325122- 괜찮아졌는데 아직도 좀 과소적합이 남아있는거 같어...
728x90