728x90
CH02 - 훈련 세트와 테스트 세트
지도 학습과 비지도 학습의 차이를 배운다. 모델을 훈련시키는 훈련 세트와 모델을 평가하기 위한 테스트 세트로 데이터를 나눠서 학습해 본다.
지도 학습과 비지도 학습
- 머신러닝 알고리즘은 크게 지도 학습과 비지도 학습으로 나눌 수 있다.
- 지도 학습 알고리즘은 훈련하기 위한 데이터와 정답이 필요하다. 지도 학습에서는 데이터와 정답을 입력(input)과 타깃(target)이라고 하고, 이 둘을 합쳐 훈련 데이터라고 부른다.
- 반면 비지도 학습 알고리즘은 타깃 없이 입력 데이터만 사용합니다.이런 종류의 알고리즘은 정답을 사용하지 않으므로 무언가를 맞힐 수가 없다.대신 데이터를 잘 파악하거나 변형하는 데 도움을 준다.
훈련 세트와 테스트 세트
- 머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 합니다.
- 이렇게 하는 가장 간단한 방법은 평가를 위해 또 다른 데이터를 준비하거나 이미 준비된 데이터 중에서 일부를 떼어 내어 활용하는 것이다.
- 평가에 사용하는 데이터를 테스트 세트, 훈련에 사용되는 데이터를 훈련 세트라고 한다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_data = [[l,w] for l,w in zip(fish_length,fish_weight)]
fish_target = [1]*35 + [0] * 14- 하나의 생선 데이터를 샘플이라고 부른다. 도미와 빙어는 각각 35마리, 14마리가 있으므로 전체 데이터는 49개의 샘플이 있다. 사용하는 특성은 길이와 무게 2개이다. 이 데이터의 처음 35개를 훈련 세트로 나머지 14개를 테스트 세트로 사용하겠다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
이제 전체 데이터에서 처음 35개를 선택해야 한다. 일반적으로 리스트처럼 배열의 요소를 선택할때는 배열의 위치, 즉 인덱스를 지정한다.
train_input = fish_data[:35]
train_target = fish_target[:35]
test_input = fish_data[35:]
test_target = fish_target[35:]
# 데이터를 준비했으니 훈련세트로 fit()메서드를 호출해 모델을 훈련하고, 테스트 세트로 score()메서드를 호출해 평가해 보겠다.kn.fit(train_input,train_target)
kn.score(test_input,test_target)
>>0.0
샘플링 편향
- 왜 정확도가 0.0으로 나올까.......
- 훈련세트와 테스트 세트를 나누려면 도미와 빙어가 골고루 섞이게 만들어야 한다.
- 일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 한다.
- 이런 작업을 간편하게 처리할 수 있도록 새로운 파이썬 라이브러리인 넘파이가 있다.
넘파이
- 넘파이는 파이썬의 대표적인 배열 라이브러리이다. 넘파이는 고차원의 배열을 손쉽게 만들고 조작할 수 있는 간편한 도구를 많이 제공한다.
import numpy as np
input_arr = np.array(fish_data) target_arr = np.array(fish_target)
print(input_arr)
>>[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]print(input_arr.shape) # 이 명령을 사용하면 (샘플 수, 특성 수)를 출력합니다.
>>(49, 2)
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
print(index)
>>[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]- 넘파이는 슬라이싱 외에 배열 인덱싱이란 기능을 제공. 배열 인덱싱은 1개의 인덱스가 아닌 여러 개의 인덱스로 한 번에 여러 개의 원소를 선택할 수 있다.
print(input_arr[[1,3]])
>>[[ 26.3 290. ]
[ 29. 363. ]]train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
print(input_arr[13],train_input[0])
>>[ 32. 340.] [ 32. 340.]test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]# 2차원 배열은 행과 열 인덱스를 콤마(,)로 나누어 지정한다. 슬라이싱 연산자로 처음부터 마지막 원소까지 모두 선택하는 경우 시작과 종료 인덱스를 모두 생략할 수 있다.
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0],train_input[:,1])
plt.scatter(test_input[:,0],test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()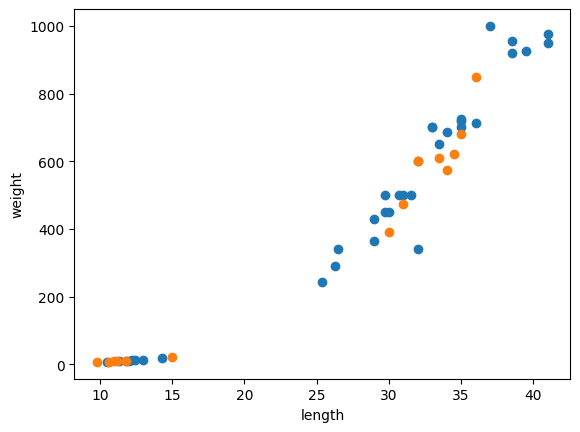
두 번째 머신러닝 프로그램
- 앞서 만든 훈련 세트와 테스트 세트로 k-최근접 이웃 모델을 훈련시켜 보자. fit() 메서드를 실행할 때마다 KNeighborsClassifier 클래스의 객체는 이전에 학습한 모든 것을 잃어버린다. 이전 모델을 그대로 두고 싶다면 KNeighborsClassifier 클래스 객체를 새로 만들어야 한다. 여기에서는 단순하게 이전에 만든 kn 객체를 그대로 사용한다.
kn.fit(train_input,train_target)
kn.score(test_input,test_target)
1.0kn.predict(test_input) # predict()메서드가 반환하는 값은 넘파이 배열이다. 사실 사이킷런 모델의 입력과 출력은 모두 넘파이 배열이다.
>>array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])test_target
>>array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])- 테스트 세트에 대한 예측 결과가 정답과 일치한다.
- 모델을 훈련할 때 사용한 데이터로 모델의 성능을 평가하는 것은 정답을 미리 알려주고 시험을 보는 것과 같다. 공정하게 점수를 매길려면 훈련에 참여하지 않은 샘플을 사용해야 한다. 이 때문에 훈련 데이터를 훈련 세트와 테스트 세트로 나누었고 훈련세트로 훈련하고 테스트 세트로 모델을 평가했다. 근데 여기서 단순히 테스트 데이터를 나누지 않고 도미와 빙어를 골고루 섞어 나누기 위해 shuffle 함수를 통해 배열의 인덱스를 섞었다.
- 지도 학습 : 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용한다. 1장에서부터 사용한 k-최근접 이웃이 지도 학습 알고리즘이다.
- 비지도 학습 : 타깃 데이터가 없다. 따라서 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는 데 주로 활용한다.
- 훈련 세트 : 모델을 훈련할 때 사용하는 데이터이다. 보통 훈련 세트가 클수록 좋다. 따라서 테스트 세트를 제외한 모든 데이터를 사용한다.
- 테스트 세트: 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많다. 전체 데이터가 아주 크다면 1%만 덜어내도 충분할 수 있다.
numpy
- seed()는 넘파이에서 난수를 생성하기 위한 정수 초깃값을 지정한다. 초깃값이 같으면 동일한 난수를 뽑을 수 있다. 따라서 랜덤 함수의 결과를 동일하게 재현하고 싶을 때 사용한다.
- arange()는 일정한 간격의 정수 또는 실수 배열을 만든다. 기본 간격은 1이다. 매개변수가 하나이면 종료 숫자를 의미한다. 0에서 종료 숫자까지 배열을 만든다. 종료 숫자는 배열에 포함되지 않는다.
- shuffle()은 주어진 배열을 랜덤하게 섞습니다. 다차원 배열일 경우 첫 번째 축(행)에 대해서만 섞습니다.
print(np.arange(3))
print(np.arange(1,3))
print(np.arange(1,3,0.2))
>>[0 1 2]
[1 2]
[1. 1.2 1.4 1.6 1.8 2. 2.2 2.4 2.6 2.8]arr = np.array([[1,2],[3,4],[5,6]])
np.random.shuffle(arr)
print(arr)
>>[[5 6]
[1 2]
[3 4]]
728x90