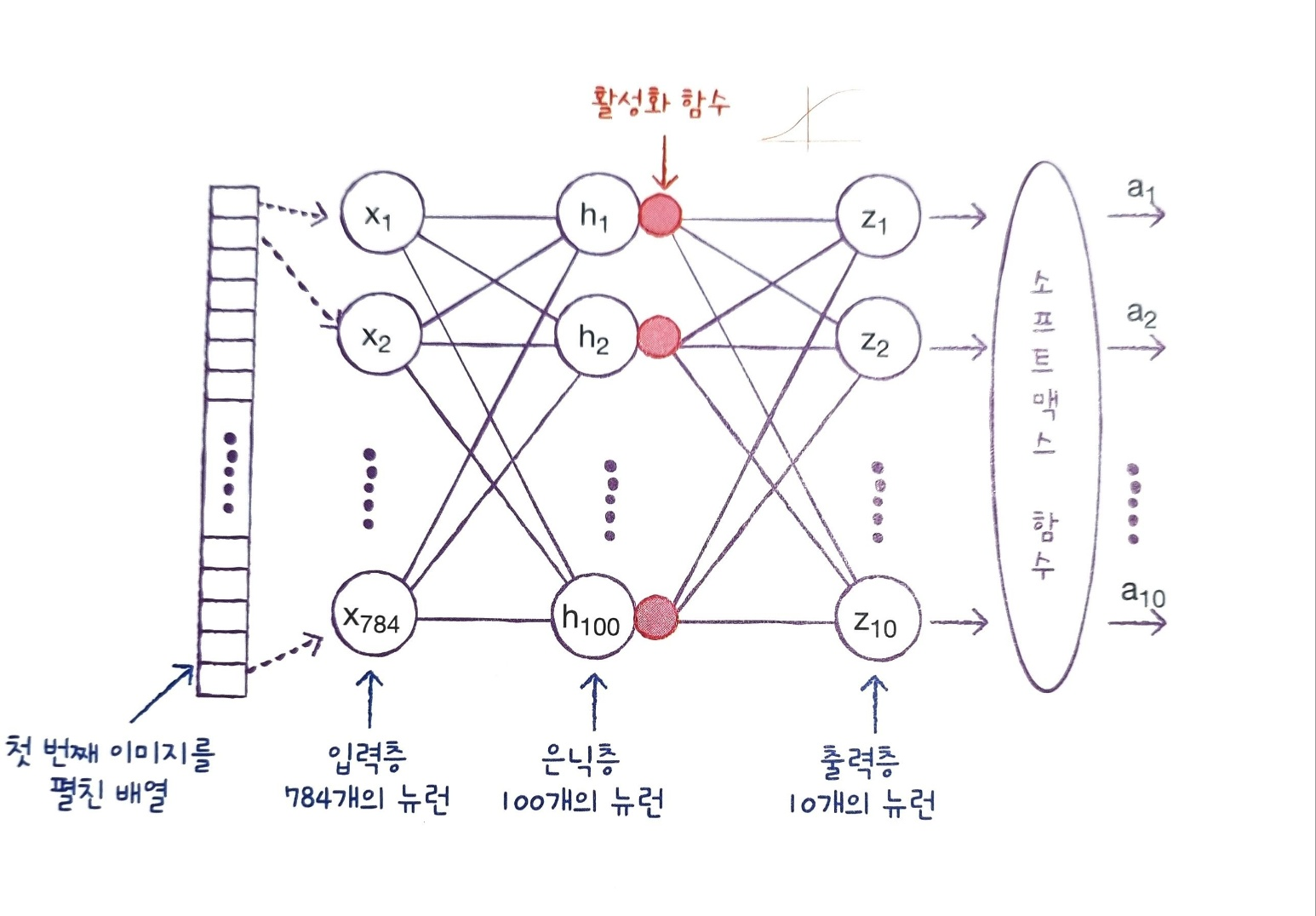
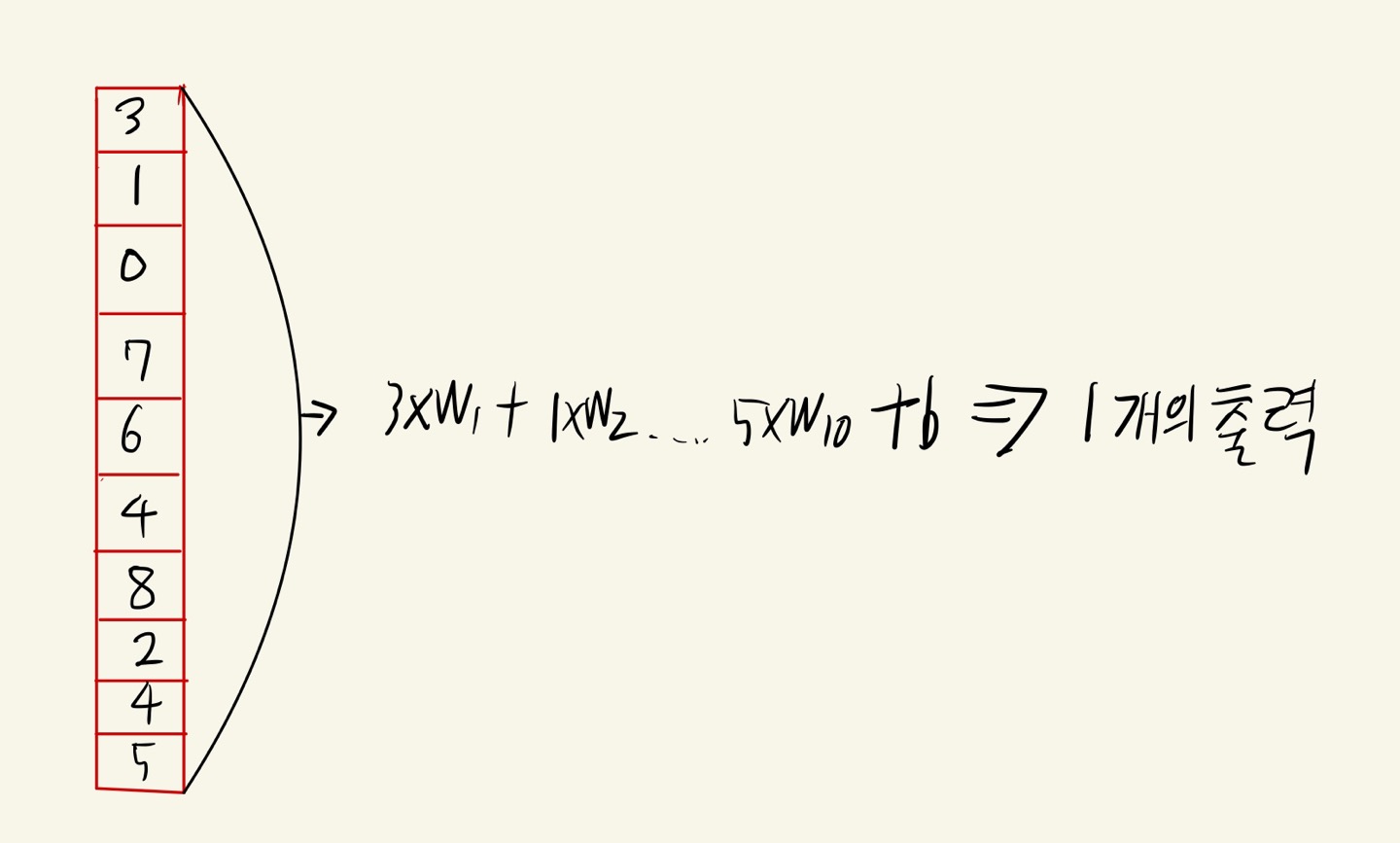합성곱 신경망의 구성 요소 합성곱 신경망을 구성하는 기본 개념과 동작 원리를 배우고 간단한 합성곱,풀링 계산 방법을 익힌다. 합성곱 합성곱은 마치 입력 데이터에 마법의 도장을 찍어서 유용한 특성만 드러나게 하는 것으로 비유할 수 있다. 7장에서 사용한 밀집층에는 뉴런마다 입력 개수만큼의 가중치가 있다. 즉 모든 입력에 가중치를 곱한다. 이 과정을 그림으로 표현하면 다음과 같다 인공 신경망은 처음에 가중치 w1~w10과 절편 b를 랜덤하게 초기화한 다음 에포크를 반복하면서 경사 하강법 알고리즘을 사용하여 손실이 낮아지도록 최적의 가중치와 절편을 찾아간다. 이것이 바로 모델 훈련이다. 결국 뉴런의 개수만큼 출력하게 된다. 합성곱은 밀집층의 계산과 조금 다르다. 입력 데이터 전체에 가중치를 적용하는 것이 아니..